Limitations of LLMs and Langchain, Problems of Agents, and TAG
Today, many AI developers use LangChain to create most of the recent LLM-based AI services. LangChain is a framework that simplifies application development by using LLMs.
Developers use LangChain as a great starting point and educational tool. However, they do not design it for real-world operational use. It is like going to Yongsan Electronics Market (Micro Center) to assemble a server yourself—building and running your pipelines and chains at a production level for business use is like purchasing and assembling every computer part by hand.
We will analyze the limitations of LLMs and LangChain, ways to overcome them, and the recently introduced Table Augmented Generation (TAG).
1. Limitations of LLMs
LLMs are AI models designed to 'generate' the most appropriate answer that 'pairs' with the question. LLMs are trained in many sample documents and produce plausible answers to a wide range of questions, which has garnered significant attention; however, a few drawbacks have soon arisen on the surface.
The first con is the hallucination phenomenon, where they provide plausible-sounding answers to things they do not know.
The second con is that many problems (such as math or physics-related computational issues) cannot be solved using a 'generative' method.
The third con is that they cannot solve problems requiring multiple reasoning steps.
Experts have noted that GPT-4o, OpenAI's latest model, has significantly improved its math (computational) capabilities. So, GPT-4o was tested with a high school-level math problem, as shown below:
If the speed of a plane is four times faster than that of a train, it takes the train 9 hours longer than the plane to travel 1,200 kilometers (about 745.65 mi).
Then, what is the speed of the train?
The following image shows the result of asking ChatGPT-4o about it. Initially, there was an error while solving the problem, but GPT-4o solved it after several retries. We can infer from this result that Python code is running in the background, and LLMs rely on LangChain to imitate calculation as a probabilistic model.

Even 'GPT-4o,' the latest model well known for significantly improved problem-solving ability in math, only achieved a score of 13% in the preliminary round of the International Mathematical Olympiad (IMO).
According to namuwiki (Wikipedia), the performance of GPT-4o is as follows: "Although its computational abilities have greatly improved, it is barely able to solve four-point level math problems in the 2024 Korean college entrance exam (CSAT), and it cannot solve any Physics 1 questions except for the fundamental conceptual questions. GPT-4o can immediately solve problems like finding the derivative of a function at a specific point if one provides the equation in an ideal form or solving a standard fourth-degree polynomial equation. However, it fails to accurately determine undetermined coefficients based on given conditions or interpret and solve basic mechanics problems that neglect friction and air resistance. This phenomenon reflects that
the AI model is not considered enough and programmed to handle mathematical structures, irrational numbers, imaginary numbers, and other related items.
It can barely manage problems up to three-point level CSAT questions; thus, based on the cutoff
grades for the calculus in 2024 CSAT, GPT-4o's performance is approximately equivalent to a
grade 5 out of 9."
2. Solutions to overcome the limitations of LLMs
To solve the first issue, Retrieval-Augmented Generation (RAG), which forces the model to answer based solely on provided reference materials, is widely used because it is considered highly effective.
A method called "Tooling" is widely applied to solve the second issue, where various tools (i.e., calculators, web search, database search, program execution, and others) are predefined. Then, the appropriate tool pair for the given input problem is selected and applied.
To solve the third issue, a technique called "Agent" is used, which breaks down the problem-solving process into multiple steps and solves each step via using Tooling (including RAG) or LLMs, and if it achieves the desired result, the process moves to the next step; otherwise, the system retries. "Agent" is a selection algorithm that interprets natural language and combines LLMs with analysis platforms. The Agent autonomously selects and organizes actions from a Pool (a collection of AIs needed for analyses that LLMs cannot perform) and sequentially executes them to provide answers. In other words, the Agent method explores solutions "autonomously" by using LLMs, RAG, and Tooling until the correct answer is obtained.
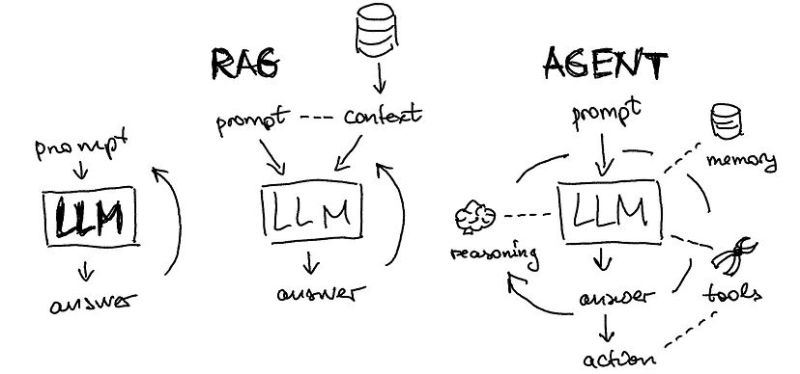
The image above conceptualizes LangChain's key modules: LLMs, RAG, and Agent. The RAG architecture enhances the LLMs with external memory, and the Agent extends this concept into memory, reasoning, tools, answers, and actions.
3. Cons of Agent Methods
When using the Agent method, predicting the outcome before executing each step is impossible. Many possibilities arise since the next step is determined based on the previous result. This approach makes it difficult to find the desired path, or even if there are few possibilities, loops between steps may occur, making the risk impossible to escape.
Also, uncertainty increases as the number of steps increases, significantly increasing the possibility of getting incorrect answers.
Moreover, users cannot tell or control the problem-solving process because the Agent autonomously handles the process. In other words, debugging becomes impossible, so it is difficult to identify where things went wrong or correct the process midway, leaving users with no choice but to restart from the beginning.
Below is an image illustrating the operating principle of an Agent.
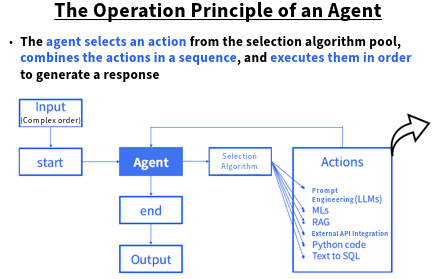
Since the Agent autonomously selects algorithms, users cannot predict the execution time, nor do they know when it will finish—there is even the possibility that it may never finish (due to an infinite loop). Also, users cannot know which algorithms are selected or executed, so it functions like a black box, like AlphaGo.
4. The Emergence of TAG
A novel approach has emerged that combines databases with the inference capabilities of LLMs to handle natural language queries that require semantic reasoning or knowledge beyond what can be directly obtained from data sources. To overcome the limitations of LLMs, following the search-augmented generation (RAG) approach that retrieves web data, this recent technology, which directly connects to databases, is called "Table-Augmented Generation (TAG)."
On September 2nd, VentureBeat, Inc. reported that researchers from UC Berkeley and Stanford University published a paper on TAG, a new paradigm for answering natural language questions using databases in archives.
According to the paper, TAG consists of three processes: "Query Synthesis," which transforms a user question into an executable database query; "Query Execution," which runs the query to retrieve relevant data; and "Answer Generation," which generates a natural language response using the data and query. These processes together enable TAG to handle a broader range of queries than systems like text-to-SQL or RAG, which are limited to specific queries.
For example, it can answer a question like, "Summarize reviews for the highest-grossing
romance movie considered a classic."
This question is difficult for traditional text-to-SQL or RAG systems because it requires identifying the highest-grossing romance movie in the database and determining through world knowledge whether the movie is considered a "classic."
However, using TAG's three-step approach, the system can generate a query for the relevant
movie data, use filters and a language model to create a table of classic romance movies ranked
by revenue, and then summarize reviews for the highest-ranked movie in the table to provide the
desired answer.
Below is an example of TAG's implementation from the paper.

According to benchmarks, the TAG baseline model consistently maintained an accuracy of over 50% across all query types and improved by 20% to 65% compared to standard baseline models. In addition, the researchers found that TAG's implementation performed query execution three times faster than other baseline models.
5. Comparison with ThanoSQL
Similar to Agents, ThanoSQL utilizes LLMs, RAG, and Tooling. However, instead of solving problems step by step like Agents (such as solving a maze by addressing each branching path in sequence), it converts the problem into a SQL query (e.g., "Give me the top 10 largest values"). It executes the query to provide the results directly to the user.
The advantages of this approach are, first, there is no risk of getting stuck in an infinite loop. Since SQL is a declarative and deterministic language, there are no issues with exploring every path or getting caught in a loop. Instead of using commands to derive results, it specifies and retrieves the desired outcome in a non-procedural manner.
Second, because the LLMs express the process used to solve the problem as a query, users can modify it immediately if LLMs solve the problem incorrectly or inefficiently to obtain an improved answer. In the ThanoSQL workspace, you can click the '>>' button at the bottom right of the chat response window to check the executed query in the Query Editor, make modifications, and rerun it.
Solving problems by converting them into SQL offers these advantages, and combining it with RAG, LLMs, and Tooling doubles the accuracy compared to relying solely on the SQL functionality provided by traditional databases, which is the main point of the TAG paper. ThanoSQL extends the capabilities of conventional SQL to incorporate these features.

Simply put, ThanoSQL can be considered a type of TAG. It incorporates not only LLMs but also RAG, external APIs, and even AI directly into SQL, maintaining the advantages of TAG even with more complex commands.
Compared to Agents, ThanoSQL always offers predictable execution times, provides accurate answers, is debuggable, and operates at significantly faster speeds.
Although TAG was introduced in a paper less than a month ago, SmartMind has been independently developing ThanoSQL since 2018. The company has applied for fourteen patents, registered twelve patents, and is pursuing six international PCT patents, with the product already commercialized.