랭체인 기반으로 AI 어플리케이션을 만들려면 비용이 얼마나 들까?
최근 LLM 서비스가 우후죽순으로 쏟아져 나오고 있지만 우리 회사에 딱 맞는 제품은 없는 것 같고 그나마 괜찮아 보이는 제품은 가격이 너무 비싸서 차라리 자체적으로 만드는 것을 검토하는 경우도 있습니다.
오늘은 기업이 랭체인 기반의 AI 어플리케이션을 만들려면 실제로 비용이 어느 정도나 필요한지 대략적으로 알아보겠습니다.
1. 랭체인 기반의 AI 어플리케이션
랭체인(LangChain)은 대규모 언어 모델(LLM)로 구동되는 어플리케이션을 빌드할 수 있는 프레임워크입니다. 랭체인은 다양한 구성요소들을 연결하는 표준 인터페이스를 제공하고 체이닝, 데이터 인식, 에이전트 등과 같은 기능을 통해 어플리케이션을 더 쉽고 빠르게 빌드할 수 있도록 해줍니다.
아래 그림은 랭체인과 에이전트가 어떻게 동작하는지를 나타냅니다.
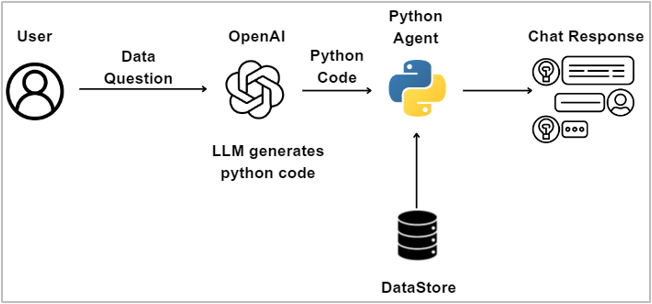
메커니즘을 간단히 설명하면, 에이전트는 백그라운드에서 Python 에이전트를 호출하여 기능하고, 이는 LLM에서 생성된 Python 코드를 실행합니다. 사용자의 질문이나 프롬프트는 LLM에서 해석하여 Python 코드로 변환하고, 생성된 코드는 실행을 위해 Python 엔진으로 전달됩니다. Python 엔진은 프로세스에 필요한 데이터에 액세스하고 읽을 수 있는 기능을 가지고 있습니다.
2. 랭체인(LLM & AI Agent) 에코시스템
아래 그림은 랭체인 에코시스템을 나타냅니다.
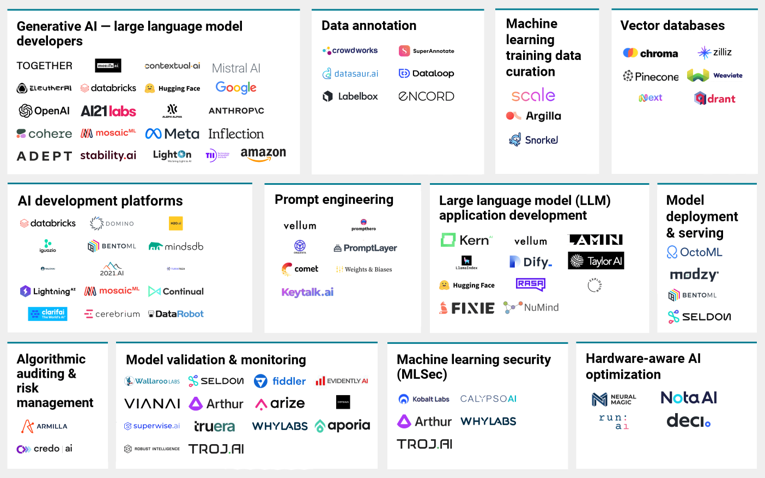
그림에서 보다시피 랭체인의 각 영역 별로 수많은 솔루션들이 있는데(심지어 이게 전부가 아닙니다), 목적과 상황에 맞게 솔루션들을 선택하고 그것들을 오케스트레이션 하는 어려운 작업은 전적으로 기업의 몫이 됩니다.
모든 영역에서 솔루션을 하나씩 골라서 각각의 비용을 모두 추정해보기는 어려우니 아래처럼 몇가지 요소들로 제한하여 살펴보도록 하겠습니다.
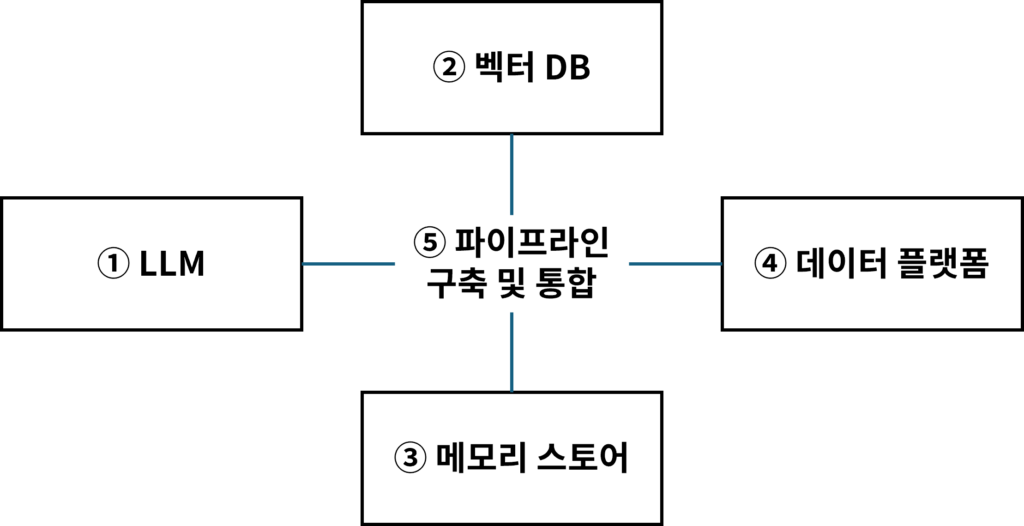
아래에서 각 요소 별로 하나씩 살펴보겠습니다.
3. 각 영역별 솔루션과 추정 비용
위의 그림에서 알 수 있듯이 랭체인 에코시스템을 구성하는 항목들은 매우 다양하지만 여기서는 편의상 몇가지로 단순화 하였습니다.
크게 LLM과 벡터DB, 인메모리 데이터 스토어, 그리고 데이터 플랫폼입니다.
대략적인 비용이 얼마나 될지 감을 잡아보기 위해서 대표적인 솔루션을 선정하고 임의의 기준에서의 비용을 산출해보겠습니다.
정확한 비용은 처리해야 할 데이터셋의 규모와 목표하는 성능 또는 품질 기준 등 개별 기업의 요구 사항에 따라 매우 크게 달라질 수 있으므로 본 게시글에 언급된 금액은 단순히 참고만 하시기를 바랍니다.
1) LLM
LLM은 컨텍스트(Context)에 따라 다르긴 하지만 대표적인 모델들의 경우 100만 토큰 기준으로 가격은 아래와 같습니다.

이를 기반으로 하루 1,000 토큰과 100만 토큰 사용량을 가정하고 연간 비용을 계산해보면 대략 아래 표와 같습니다.
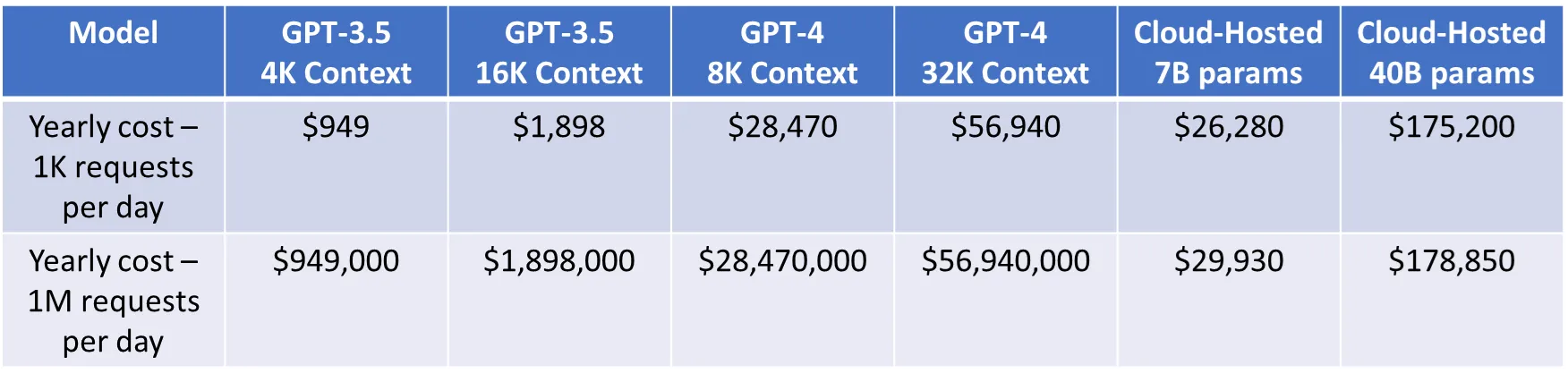
OpenAI의 경우 연간 비용은 모델에 따라 사용량이 적을 때(하루 1,000개 토큰)는 연간 1,000 ~ 50,000달러이고, 사용량이 많을 때(하루 100만개 토큰) 는 연간 100만~5,600만 달러입니다.
반면에 Falcon-7B, LLaMa2-7B, Vicuna-33B 같은 오픈소스 모델의 호스팅 비용은 사용량이 많은 경우에 OpenAI 대비 상대적으로 매우 낮은 비용이 드는 것을 알 수 있습니다.
2) 벡터 DB
벡터DB는 대표적인 솔루션으로 파인콘(Pinecone)을 선정하였고, 비용 계산을 위해 아래처럼 임의의 기준을 설정하였습니다.
- P1.x8 pod 4개 사용 : 월 $3,300
- 임베딩 생성에 대한 일회성 비용 : $3,300
- 임베딩 모델이 변경될 때마다 추가 : $3,300
- 추가적으로 쿼리 임베딩 서비스와 응답 생성에 대한 추가 반복 비용이 발생 : +a
+a는 0으로 가정하고 위 금액에 12를 곱하여 연간 금액을 계산해보면 약 1.64억원이 됩니다.
(다시 말씀드리지만 이 금액은 절대적인 기준이 아니며 단순 참고용으로만 이해해 주시기 바랍니다.)
위의 기준은 비교적 작은 데이터 세트이며 고성능을 위한 런타임 설정이 아니라는 점을 유의해야 합니다. 이러한 설정을 사용하면 데이터베이스 용량은 초당 30개의 쿼리에 불과합니다. 즉 이 속도로는 1,000만 개의 벡터를 초기화하는 데 4일이 걸립니다. 만약 이러한 성능과 속도에 만족하지 못한다면 더 많은 replica가 필요합니다. 그렇게 되면 비용은 이 계산보다 훨씬 더 커지게 됩니다. 대규모 말뭉치(corpora, 데이터 집합)를 보유한 기업은 RAG 애플리케이션을 만들기 위해서 10~100배 더 많은 비용을 지불해야 할 수도 있습니다.
3) 인메모리 데이터 스토어
인메모리 데이터 스토어는 milli-second 이하의 데이터 액세스, 확장성, 고가용성을 제공하는 인메모리 DB입니다.
인메모리 데이터 스토어로 대표적인 솔루션으로 레디스(Redis)를 선정하였고 비용 계산을 위해 아래처럼 임의의 기준을 설정하였습니다.
- 사용 Node : 1개
- Memory : 128GB
- CPU cores : 20
- Storage : 2TB
- Backups : 14일
위와 같은 사양으로 Managed Service 형태로 사용하면 시간당 요금은 약 $6이고 월 금액은 $4,300입니다. 여기에 12를 곱하여 연간 금액을 계산해보면 약 0.71억원이 됩니다.
4) 데이터 플랫폼
현재 시장을 리딩하는 데이터 플랫폼 솔루션으로는 데이터브릭스(Databricks), 스노우플레이크(Snowflake), 데이터이쿠(Dataiku) 등이 있습니다.
모든 데이터 플랫폼의 비용은 사용량에 따라 달라지므로 한마디로 비용이 얼마다 라고 잘라 말할 수는 없습니다.
오픈된 정보가 많이 없긴하지만 데이터브릭스는 미국 기준으로 중견 기업의 평균 데이터 사용량을 기준으로 볼 때 중견 기업의 지출은 연간 10만 달러에서 100만 달러 사이인 것으로 알려져 있습니다.(출처)
즉, 연간 금액이 약 1.38억원~13.8원억 정도 됩니다.
5) 파이프라인 구축과 통합
마지막으로 랭체인의 에코시스템을 구성하는 모든 항목들을 연계하여 파이프라인을 구축하고 통합하는 비용이 있습니다. 이 부분은 기준을 설정하기도 어렵고 케이스마다 모두 다를 수 있어서 비용 산정을 하지는 않겠습니다.
다만, 파이프라인 구축과 통합은 다수의 전문 인력이 상당 시간 투입되어야 하는 난이도가 높은 작업이며 결코 작지 않은(어쩌면 가장 클 수도 있는) 비용이 발생할 것이라는 점을 염두에 두셔야겠습니다.
그리고 MLOps나 LLMOps 등과 관련된 보이지 않는 추가적인 비용도 발생하게 됩니다.
1번부터 5번까지 모두 다 합하면 얼마가 될까요? 네 그렇습니다, 랭체인 기반으로 AI 어플리케이션을 만드는 것은 아~주 비쌉니다. 가격이 비쌀뿐만 아니라 수많은 요소들을 조화롭게 오케스트레이션하고 운영 및 유지보수도 해야 합니다. 바로 이런 이유 때문에 대부분의 기업들이 AI 도입을 어려워하고 도입을 시작하더라도 실패하는 경우를 볼 수 있습니다.
4. 데이터 플랫폼을 꼭 사용해야 할까?
위에서 살펴본 비용 요소 중 LLM을 제외하면 데이터 플랫폼의 비중이 가장 큰데요, 현재 AI 어플리케이션을 랭체인 기반으로 개발하려면 거의 대부분의 경우 데이터 플랫폼을 필수적으로 사용하게 됩니다. 물론 데이터 플랫폼 솔루션을 사용하지 않고도 AI 서비스를 만들 수는 있지만 자체적으로(또는 외주) 개발해야 할 것들이 굉장히 많고 개발의 난이도 또한 매우 높아지게 됩니다.
아래 표에서는 데이터 플랫폼 사용 여부에 따른 각 방식별 특징과 비용, 난이도 등을 간단하게 비교하였습니다.

위 표에 언급한 솔루션 비용과 인건비 등은 특정 조건에서의 대략적인 금액이며 비교를 위한 참고용입니다.
5. 마치며
랭체인은 LLM과 Prompt engineering, RAG, Text to SQL, 다른 머신러닝 서비스 및 외부 API들을 모두 사용할 수 있도록 준비된 오픈소스 툴키트 입니다.
RAG와 Prompt Engineering을 사용하기 위해서는 벡터 DB와 인메모리 데이터 스토어가 반드시 필요하고, 다른 머신러닝 모델을 사용하기 위해서는 데이터 플랫폼이 필요합니다.
랭체인은 일종의 규약으로 어떤 솔루션이 그 규약에 맞추기만 한다면 랭체인 기능 내에 통합될 수 있습니다. 고객 관점에서는 랭체인을 쓰더라도 벡터 DB, 인메모리 데이터 스토어, 데이터 플랫폼 등 필요한 솔루션들을 일일이 선택해야 하며 비용 또한 각각 개별로 지불해야 합니다.
한편 데이터 분석 및 머신러닝 개발에 사용하는 데이터 플랫폼은 LLM 및 GPT 모델 전에 개발된 서비스들이기 때문에 데이터를 벡터 DB에 저장하고 처리하지 않습니다. 다시 말하면 이미지, 비디오, 텍스트 등으로 구성된 비정형 데이터를 데이터 플랫폼 내의 값비싼 데이터 스토리지에 저장해야 함을 의미합니다.
만약 기업이 랭체인 방식이 아닌 ThanoSQL을 사용하여 AI 어플리케이션을 개발한다면 위와 같은 복잡한 문제들이 모두 한번에 해결됩니다.
또한 ThanoSQL은 랭체인 방식 대비 정확도 및 실행 속도가 월등하면서도 비용까지 저렴한데요, 그 이유는 LLM 뿐 아니라 다른 머신러닝을 개발할 때에도 트랜스포머(Transformer) 모델을 사용하므로 내장된 벡터 DB를 적극 활용하기 때문입니다. 즉 원천 데이터는 매우 싼 S3 같은 분산 스토리지에 저장해 두고, 실제 분석에 사용되는 데이터는 모두 크기가 월등히 작은 임베딩 벡터 형태로 변환하여 벡터 DB에 저장 및 처리하는 방식입니다.
ThanoSQL은 LLM 및 기타 머신러닝(분석)에도 트랜스포머 모델이 사용 가능하도록 되어있기 때문에 비로소 TAG 방식(SQL내에서 LLM, prompt engineering, RAG, text to SQL, 또다른 MLs, 외부API 를 사용할 수 있는 구조)이 동작할 수 있습니다.