LLM으로 대화하듯이 데이터 분석하기
우리 회사도 LLM을 도입해야 할까?
현재 LLM 분야에서 파운데이션 모델 쪽은 과하다 싶을 만큼 많은 투자가 이루어지고 있습니다. 그러나 투자자들과 기업들은 실제로 ROI는 어떻게 되는지, 구체적인 수익 모델은 어떻게 되는지 의문이 커져가고 있는 상황입니다.
테슬라는 깃허브(GitHub)의 코파일럿(Copilot)을 사용해서 코딩 작업의 80%를 한다고 밝혔을 정도로 기업의 IT 부문에서는 이미 생성형 AI와 LLM을 상당히 높은 수준으로 활용하여 경쟁력과 생산성을 극대화하고 있습니다. 그러나 비 IT 부문의 경우는 기업 내부 데이터의 외부 유출에 대한 우려와 기술의 복잡성으로 인한 높은 비용으로 인해 생성형 AI 도입이 상대적으로 저조한 실정입니다. 그나마도 주로 챗봇을 통해 회사 내부의 규정이나 회사생활 가이드에 대한 질의응답 등을 하는 수준이 대부분이며, 직접적인 생산성 향상이나 비즈니스 인사이트 도출에 활용하지는 못하고 있는 것으로 보입니다.
그래서 스마트마인드는 바로 그 포인트, 즉 비IT 부문의 생산성 향상에 집중하고자 합니다. 스마트마인드의 솔루션 ThanoSQL은 기업 내부의 원천 데이터를 외부로 유출하지 않으며 LLM과 데이터 분석을 하나로 통합한 올인원 플랫폼입니다.
LLM으로 비IT 부문의 생산성을 어떻게 향상시킬 수 있나요?
대표적인 비IT 부문인 세일즈/마케팅 분야를 예로 들면, 담당자의 일상 업무를 자동화하거나 업무 영역을 넓게 확장함으로써 생산성이 향상될 수 있습니다. 일상 업무 자동화는 RPA가 잘하는 영역이므로 스마트마인드는 담당자의 업무 영역을 확장하는데 도움을 드리고자 합니다.
아마도 기존의 업무는 RDB(관계형 데이터베이스)에 있는 정형 데이터를 엑셀로 export하거나 BI툴로 연결해서 여러 형태로 pivot해보는 차원이었을 겁니다. 또한 RDB가 아닌 NoSQL이나 데이터 레이크 등에 저장된 비정형 데이터에 대한 분석은 IT 부서의 도움을 받아야만 가능할 것이며, 각각의 분석 결과들에 대한 유기적인 결합이나 통합적인 인사이트를 찾는 것은 굉장히 어려운 일이 될 것입니다.
하지만 ThanoSQL을 사용한다면 이 모든 것들을 자연어로 대화하듯이 쉽게 할 수 있으며 IT 부서의 도움 없이도 누구나 모든 종류의 데이터에 대해서 분석이 가능합니다.
예를 들어 다음과 같은 유스 케이스(Use Case)를 생각해보겠습니다.
고객 리뷰 중에 부정적인 피드백들을 찾아서 카테고리를 구분해줘 -> 그중 품질에 대한 불만이 가장 많은 제품을 골라줘 -> 해당 제품의 올해 2분기 판매량을 알려줘 -> 작년 동분기와 비교해줘
각 단계별 흐름은 아래 그림들과 같습니다.
첫번째 그림은 ThanoSQL 워크스페이스의 초기 화면입니다. 먼저 분석하고자 하는 대상 데이터가 저장된 테이블을 선택하고 입력창에 질문을 입력하는 것으로 분석을 시작하게 됩니다.
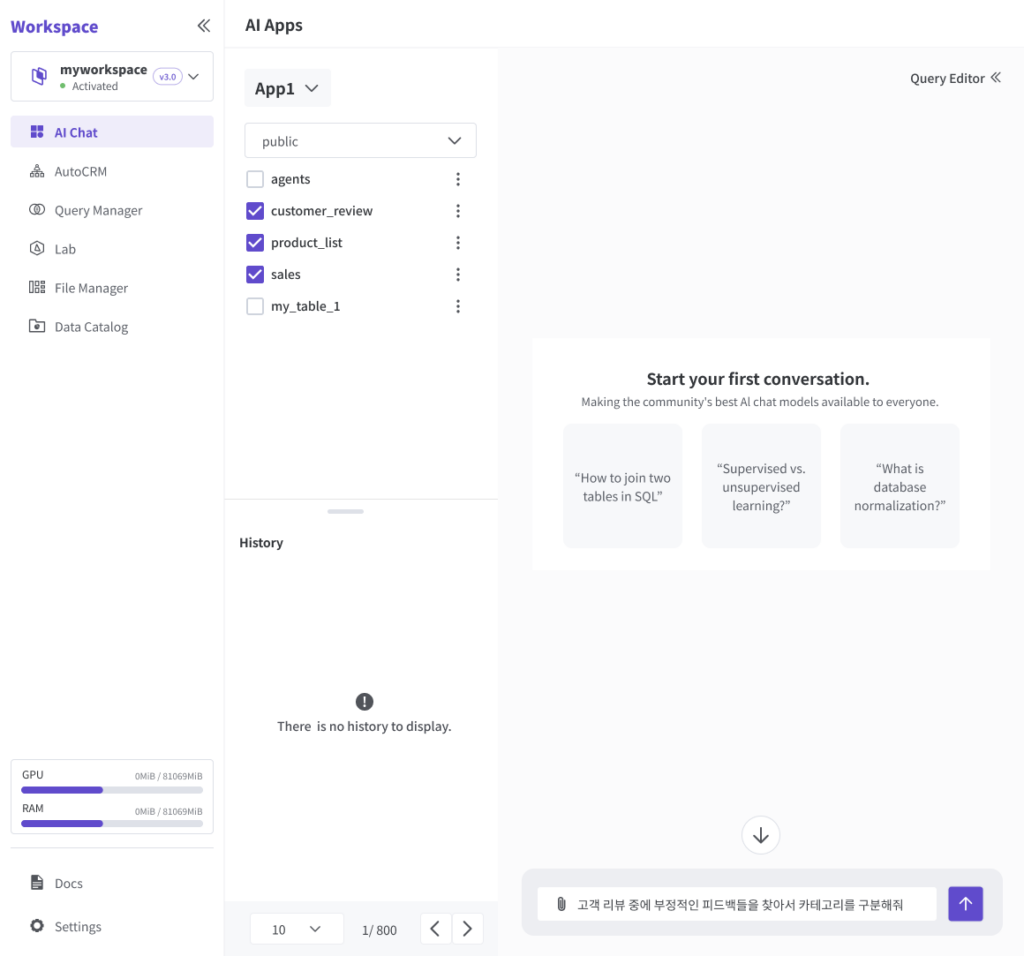
위 예시에서는 먼저 고객의 리뷰를 분석해야 하므로 customer_review 테이블을, 그 다음으로 제품을 찾아야 하므로 product_list 테이블을, 마지막으로 판매량을 확인해야 하므로 sales 테이블을 선택하였습니다.
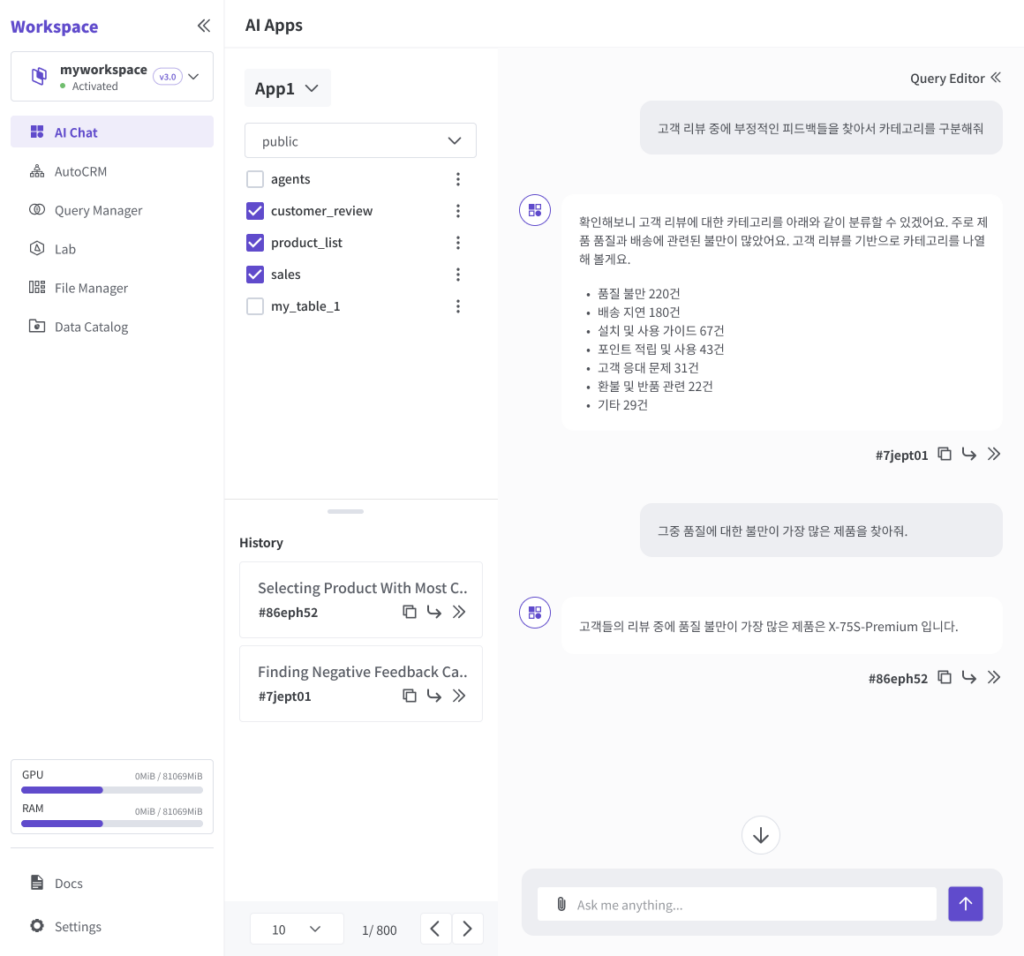
자연어로 입력된 질문은 ThanoSQL 내부에서 자동으로 SQL구문으로 변환되어 선택한 테이블들을 대상으로 실행되는데, 이때 여러가지 AI 알고리즘과 머신 러닝 기법들이 적용됩니다. 여기서 사용되는 알고리즘과 모델들은 ThanoSQL이 기본적으로 제공하는 것이며 사용자가 원한다면 허깅페이스 등에서 외부의 모델을 가져와서 사용할 수도 있습니다. 그리고 그렇게 분석된 실행 결과는 다시 LLM을 통해 자연어 형태로 만들어져서 대답창에 나타나게 됩니다.
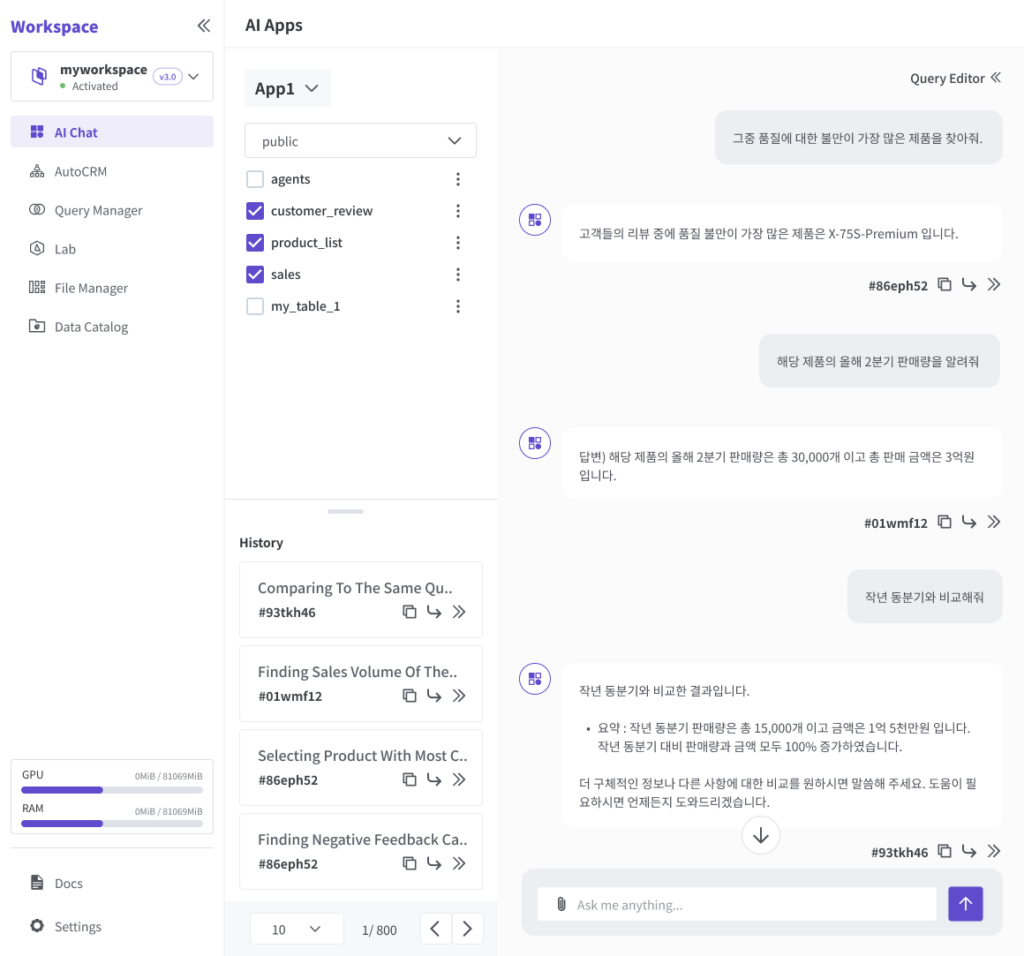
사용자는 단지 몇번의 자연어 입력만으로 고객 리뷰 같은 비정형 데이터와 세일즈/마케팅 같은 정형 데이터를 결합해서 분석하고 결과를 즉시 확인할 수 있습니다.
즉 ThanoSQL은 정형 데이터와 비정형 데이터가 모두 테이블로 저장된 DB에 머신 러닝과 LLM을 결합하여 대화형으로 분석할 수 있는 분석 도구입니다. 따라서 ThanoSQL을 사용하면 위의 예시처럼 IT에 대한 전문적인 지식이 없어도 사내의 모든 데이터에 대해서 빠르게 분석할 수 있고, 그 결과로부터 의미 있는 인사이트도 찾을 수 있게 됩니다.
랭체인 기반의 다른 솔루션과의 차이점은 무엇인가요?
일반적으로 랭체인 기반으로 LLM 서비스를 개발하기 위해 필요한 기술 스택은 다음 그림과 같습니다.
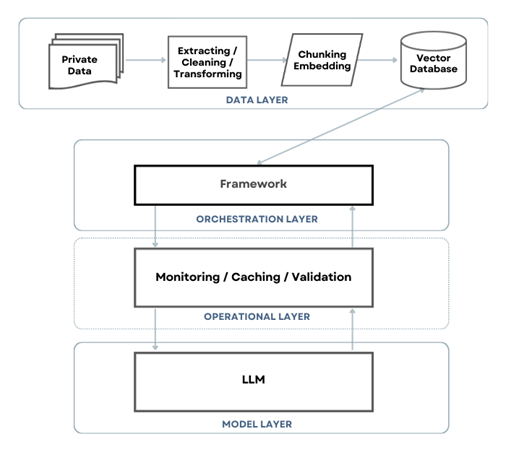
각 계층별로 또 계층 내에서도 각 요소별로 선택 가능한 제품들은 아래와 같이 매우 다양합니다. 심지어 이 표에 있는 것들이 전부 다가 아닙니다.

랭체인 기반의 LLM 서비스를 구축하고 자체 기술 스택에 통합하려는 기업들은 위와 같은 데이터 전문가들이 필요로 하는 굉장히 많은 도구들을 일일이 선정하고 구매해서 연결하고 운영까지 해야 합니다.
대부분의 기업들은 이런 역량이 부족한 것이 현실이고 단절된 도구들과 서비스들을 유기적으로 통합해야 하므로 LLM 도입은 엄청난 시간과 비용, 전문 인력을 필요로 합니다.
반면 ThanoSQL을 도입하면 그런 고민과 노력들은 모두 필요 없게 됩니다. 사용자는 단지 LLM 모델로 챗GPT 4.0을 사용할지 아니면 허깅페이스에 있는 오픈소스 모델을 사용할 것인지만 결정하면 됩니다.
또 다른 차이점은 데이터 분석에 대한 유연성과 신속성입니다. 아래 그림은 ThanoSQL을 사용해서 고객 상담 센터의 어느 직원이 고객과 가장 오랜 시간을 통화했는지 찾는 예시입니다.
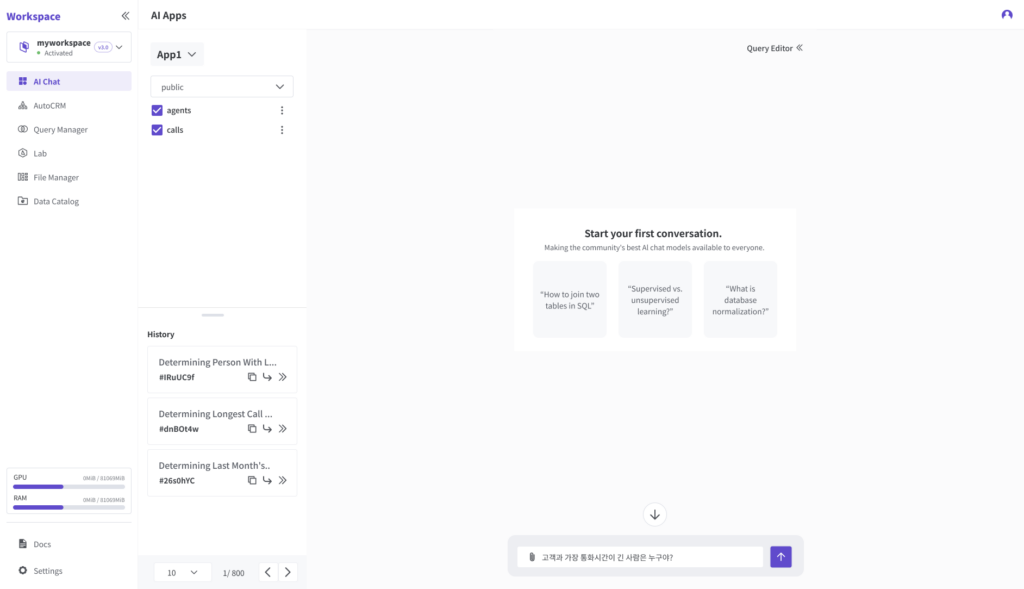
다음 그림에서는 사용자가 입력한 자연어 질문이 어떻게 SQL로 변환되었고 그 실행 결과는 무엇인지 확인할 수 있습니다.
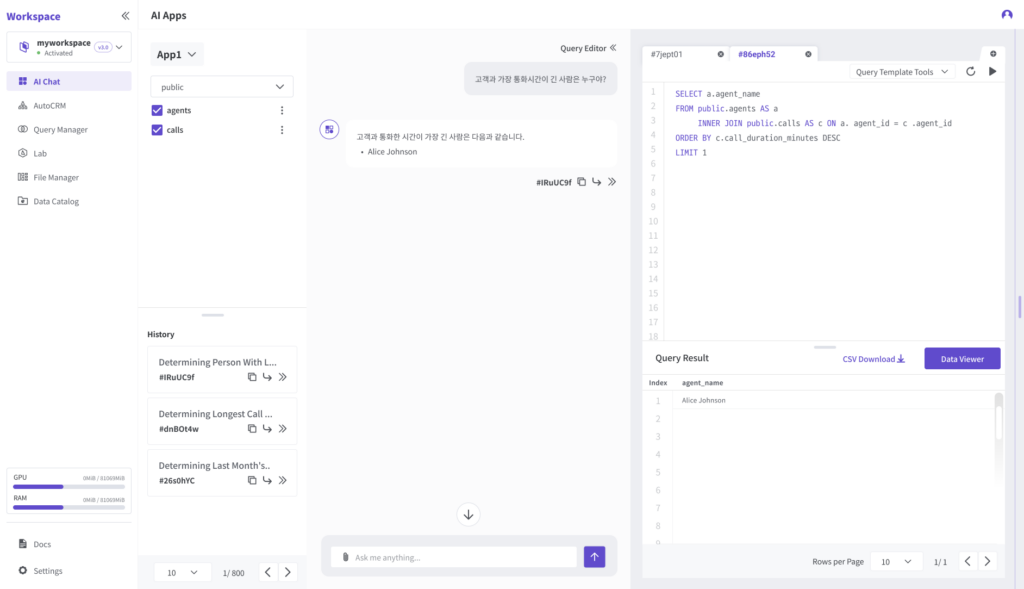
만약 처음 질문과 다른 분석이 필요하다면 SQL 구문을 즉시 수정하고 바로 실행하여 결과를 확인할 수도 있습니다.
반면 랭체인은 파이썬 기반이므로 해당 부분이 함수 형태로 제공되어 블랙박스일 뿐만 아니라 사용자가 원하는 대로 빠르게 수정도 불가능합니다.
마치며
랭체인 기반으로 LLM 서비스를 구축하려면 SI 프로젝트를 진행하듯이 복잡다양한 기술 스택들을 통합해야 하고 워크플로우의 개발도 수없이 반복해야 합니다. 따라서 시간과 비용 뿐만 아니라 사용 편의성 측면에서도 LLM과 데이터 분석을 단일 플랫폼 형태로 제공하는 ThanoSQL을 도입하는 것이 모두에게 효율적인 의사결정이 될 것입니다.